中俄语料库与机器学习研究实践
第一部分:环境准备
1. 安装Python
- 访问Python官网:https://www.python.org/downloads/windows/
- 下载最新的Python 3.10版本(不推荐3.11或更高版本,因为有些库可能兼容性问题)
- 运行安装程序,务必勾选"Add Python to PATH"
- 点击"Install Now"进行安装
- 安装完成后,打开命令提示符(CMD)或PowerShell,输入
python --version确认安装成功
2. 创建虚拟环境
虚拟环境可以避免不同项目之间的依赖冲突:
# 打开命令提示符(以管理员身份运行)
cd C:\Users\您的用户名\Documents
mkdir word_sense_project
cd word_sense_project
# 创建虚拟环境
python -m venv venv
# 激活虚拟环境
venv\Scripts\activate
然后再安装一些必要的库
pip install torch torchvision torchaudio
pip install transformers datasets pandas numpy scikit-learn matplotlib
第二部分:数据准备
https://ruscorpora.ru/ 俄罗斯国家语料库
http://ccl.pku.edu.cn:8080/ccl_corpus/index.jsp 北京大学 中国语言学研究中心
俄罗斯国家语料库可以下载CSV格式的,这种格式适合python分类整理,我们选择这个来下载。
其文件的抬头如下:
"Reversed left context";"Reversed center";"Left context";"Center";"Punct";"Right context";"Title";"Author";"Birthday";"Header";"Created";"Sphere";"Type";"Topic";"Publication";"Publ_year";"Medium";"Ambiguity";"Sentences";"Words";"Audience_age";"Audience_level";"Audience_size";"Full context";"Example source"
我们可以看见,这样的分类很让人头疼,但是我们可以用python来帮忙。
初筛数据
我们可以把让人头疼的语料库的文件归纳成这样:
分为sentence,target_word
(其实还有一个sense_id,我们之后再讨论)
sentence,target_word
"Российское руководство многократно подчёркивало, что жители Крыма сделали свой выбор демократическим [TGT]путём[/TGT], в соответствии с международным правом и Уставом ООН.",путём
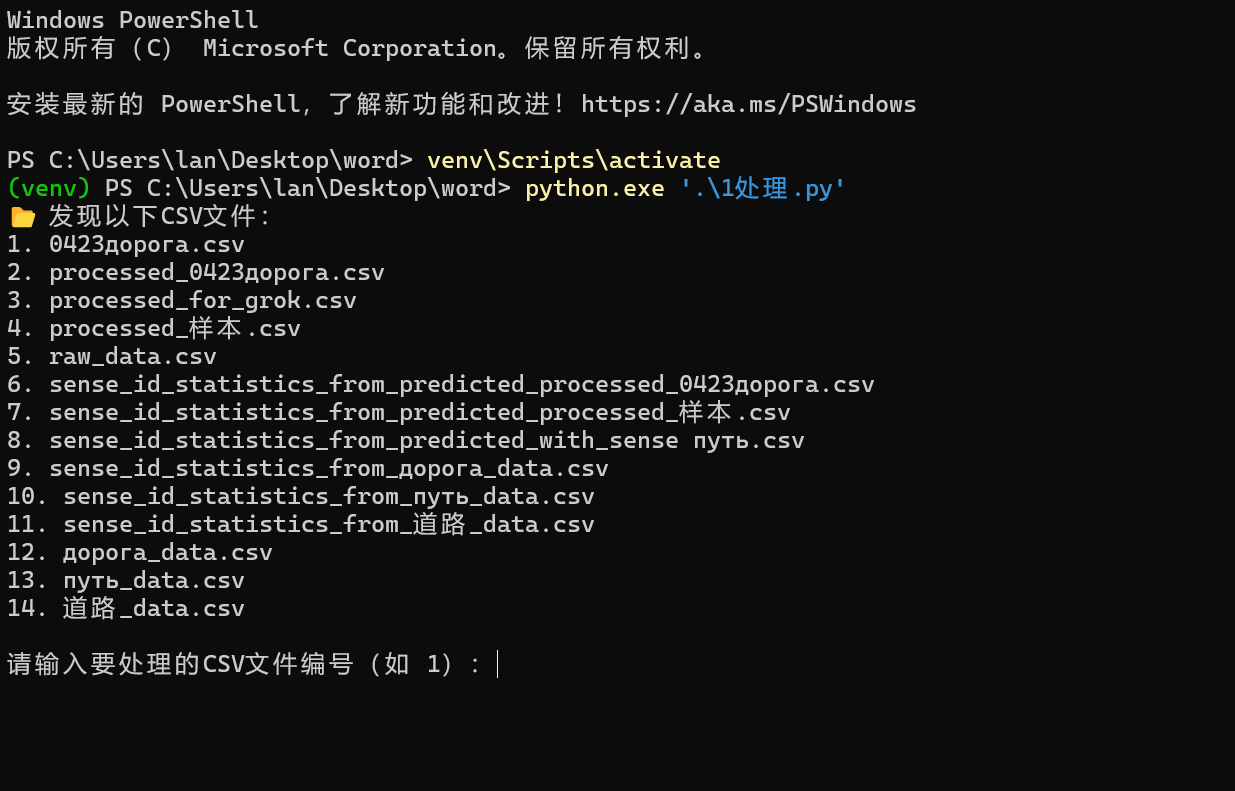
我自用的语料库初筛python脚本如下
import pandas as pd
import re
import os
# --- 列出当前目录下所有CSV文件 ---
csv_files = [f for f in os.listdir('.') if f.endswith('.csv')]
if not csv_files:
print("❌ 当前目录下没有CSV文件。请放入CSV文件后重试。")
exit()
print("📂 发现以下CSV文件:")
for i, file in enumerate(csv_files, start=1):
print(f"{i}. {file}")
# --- 让用户选择文件 ---
while True:
try:
choice = int(input("\n请输入要处理的CSV文件编号(如 1):"))
if 1 <= choice <= len(csv_files):
input_path = csv_files[choice - 1]
break
else:
print("⚠️ 请输入有效的编号!")
except ValueError:
print("⚠️ 请输入数字!")
# --- 自动生成输出文件名 ---
output_path = f"processed_{input_path}"
# --- 读取CSV ---
df = pd.read_csv(input_path, sep=';', encoding='utf-8')
# --- 存储处理结果 ---
output_data = []
for idx, row in df.iterrows():
full_context = str(row['Full context'])
center_word = str(row['Center'])
if pd.isna(full_context) or pd.isna(center_word):
continue
center_word = center_word.strip()
pattern = r'\b' + re.escape(center_word) + r'\b'
if re.search(pattern, full_context):
sentence_tagged = re.sub(pattern, f"[TGT]{center_word}[/TGT]", full_context, count=1)
output_data.append({
"sentence": sentence_tagged,
"target_word": center_word
})
else:
print(f"⚠️ 找不到词 {center_word} 在句子中: {full_context}")
# --- 保存处理结果 ---
df_out = pd.DataFrame(output_data)
df_out.to_csv(output_path, index=False, encoding="utf-8")
print(f"\n✅ 处理完成!输出文件:{output_path}")
效果如下:
数据筛选好了之后,可以选择手动给上千个例句标注,但是我不建议这么做,因为会累死人。
AI赋能,对齐颗粒度
使用grok和deepseek的API来标注例句的关键词的意思,这样效率会很快,5000个例句大概2小时可以标注完毕。
当然要使用prompt,比如道路就是:
请判断以下句子中“[TGT]道路[/TGT]”一词的具体含义。请从以下9个类别中选择最适合的一个,并返回其类别名称:
1. 地面道路(地面上供人或车马通行的部分)
2. 路途(路程、行进过程)
3. 路人(道路上的人)
4. 奔走(艰难的移动或跋涉)
5. 职业(职业或行业)
6. 线索(去向、追踪方向)
7. 方法(实现目标的办法)
8. 样子(行动的样子、方式)
9. 油水(可获取的好处、利益)
句子:
{sentence}
请只返回类别名称,例如“地面道路”,不要编号,不要解释。
示例脚本如下:
import pandas as pd
import os
import time
import random
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor, as_completed
from openai import OpenAI
# --- 配置 DeepSeek API ---
client = OpenAI(
api_key=" ", # ✅ 替换为你的 API 密钥
base_url="https://api.deepseek.com/v1"
)
# --- 选择CSV文件 ---
csv_files = [f for f in os.listdir('.') if f.endswith('.csv')]
if not csv_files:
print("❌ 当前目录下没有CSV文件!")
exit()
print("📁 当前目录下的CSV文件:")
for i, file in enumerate(csv_files, start=1):
print(f"{i}. {file}")
while True:
try:
choice = int(input("\n请输入要处理的CSV编号(如 1):"))
if 1 <= choice <= len(csv_files):
input_path = csv_files[choice - 1]
break
else:
print("⚠️ 输入编号无效,请重新输入。")
except ValueError:
print("⚠️ 请输入数字!")
output_path = f"predicted_{input_path}"
df = pd.read_csv(input_path, encoding='utf-8')
# 初始化空列
if "sense_id" not in df.columns:
df["sense_id"] = ""
if "sense_group" not in df.columns:
df["sense_group"] = ""
# --- 细义 → 大类映射 ---
group_mapping = {
"地面道路": "实体与移动类",
"路途": "实体与移动类",
"路人": "实体与移动类",
"奔走": "实体与移动类",
"职业": "抽象发展类",
"方法": "抽象发展类",
"样子": "抽象发展类",
"线索": "指向与追踪类",
"油水": "利益/资源类"
}
# --- 请求函数 ---
def query_deepseek(sentence):
prompt = f"""
请判断以下句子中“[TGT]道路[/TGT]”一词的具体含义。请从以下9个类别中选择最适合的一个,并返回其类别名称:
1. 地面道路(地面上供人或车马通行的部分)
2. 路途(路程、行进过程)
3. 路人(道路上的人)
4. 奔走(艰难的移动或跋涉)
5. 职业(职业或行业)
6. 线索(去向、追踪方向)
7. 方法(实现目标的办法)
8. 样子(行动的样子、方式)
9. 油水(可获取的好处、利益)
句子:
{sentence}
请只返回类别名称,例如“地面道路”,不要编号,不要解释。
"""
for attempt in range(3):
try:
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
)
return response.choices[0].message.content.strip()
except Exception:
time.sleep(2 ** attempt)
return "请求失败"
# --- 多线程并发任务函数 ---
def process_row(idx, sentence):
prediction = query_deepseek(sentence)
return idx, prediction
# --- 构造任务池(过滤已处理)
tasks = [(i, row['sentence']) for i, row in df.iterrows()
if not isinstance(row.get('sense_id'), str) or not row['sense_id'].strip()]
# --- 开始并发处理
MAX_WORKERS = 5 # ✅ 控制并发线程数(可调高至8或10)
print(f"\n🚀 启动并发处理,共需处理 {len(tasks)} 条(线程数:{MAX_WORKERS})\n")
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
futures = {executor.submit(process_row, idx, sentence): idx for idx, sentence in tasks}
for i, future in enumerate(tqdm(as_completed(futures), total=len(futures), ncols=100, desc="🚀 处理中")):
idx, prediction = future.result()
df.loc[idx, 'sense_id'] = prediction
df.loc[idx, 'sense_group'] = group_mapping.get(prediction, "未知")
# 每50条保存一次
if (i + 1) % 50 == 0 or (i + 1) == len(futures):
df.to_csv(output_path, index=False, encoding='utf-8')
tqdm.write(f"💾 自动保存至 {output_path},进度:{i+1}/{len(futures)}")
# --- 最终保存
df.to_csv(output_path, index=False, encoding='utf-8')
print(f"\n🎉 全部完成!预测结果保存在:{output_path}")
然后查看终端的提示,打开输出的文件,你会发现多了一列sense_id,这就是赛博教授标注的意思。
sentence,target_word,sense_id
"Российское руководство многократно подчёркивало, что жители Крыма сделали свой выбор демократическим [TGT]путём[/TGT], в соответствии с международным правом и Уставом ООН.",путём,手段与方法
你会发现,赛博教授有时候会抽风,会不按照你的prompt去做事情,会在sense_id这一列输出一些英文,这个时候你可以选择WPS(你不会觉得这很不专业吧?大错特错!我一开始采用的python脚本来筛选,结果发现还没这个直观和快)打开这个CSV,在C列全选,然后审阅识图点击重复项,用眼睛过一遍,不是重复项的(因为是AI自己的词)直接删了,不影响大局。
这之后,符合训练的训练集你已经准备好了。
第三部分 调试训练脚本
这是一个用于词义消歧(Word Sense Disambiguation)的PyTorch训练脚本。该脚本的主要功能是训练一个基于预训练语言模型的词义消歧模型,能够根据上下文确定多义词的具体含义。
主要功能:
-
设备选择:根据环境自动选择使用DirectML、CUDA或CPU设备进行训练
-
数据处理:
- 使用预训练的分词器处理文本数据
- 支持加载单个或多个数据文件
- 自动划分训练集和验证集
-
模型训练:
- 使用预训练语言模型(默认为bert-base-multilingual-cased)
- 实现了完整的训练循环,包括梯度裁剪
- 使用AdamW优化器和余弦退火学习率调度器
- 提供了断点续训功能
-
早停和模型保存:
- 实现了早停机制,当验证集准确率连续多轮不提升时停止训练
- 保存训练过程中验证集准确率最高的模型
- 同时保存最终模型
-
训练可视化:
- 绘制并保存训练损失和验证准确率曲线
-
参数配置:
- 通过命令行参数灵活配置训练参数
- 包括数据文件路径、模型名称、输出目录、训练轮数、批次大小等
这个脚本展示了一个完整的深度学习训练流程,特别适用于NLP中的词义消歧任务,同时兼顾了多种设备支持和训练优化技术。
import torch
import torch.nn as nn
import os
import time
import argparse
import matplotlib.pyplot as plt
from torch.optim import AdamW
from torch.optim.lr_scheduler import CosineAnnealingLR
from transformers import AutoTokenizer
from sklearn.metrics import accuracy_score
from tqdm import tqdm
try:
import torch_directml
directml_available = torch_directml.is_available()
except ImportError:
directml_available = False
from torch.cuda.amp import GradScaler
from data_utils import load_data
from model import WordSenseModel
def train(args):
# 设置设备
if directml_available:
device = torch_directml.device()
print(f"使用 DirectML 设备: {torch_directml.device_name(0)}")
else:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
os.makedirs(args.output_dir, exist_ok=True)
# 加载分词器
print("加载分词器...")
try:
tokenizer = AutoTokenizer.from_pretrained(args.model_name)
except Exception:
print("分词器加载失败,回退到 bert-base-multilingual-cased")
tokenizer = AutoTokenizer.from_pretrained('bert-base-multilingual-cased')
# 加载数据
data_files = args.data_files.split(',') if args.data_files else [args.data_file]
print(f"加载数据文件: {data_files}...")
train_dataloader, val_dataloader, sense_to_id, id_to_sense = load_data(
data_files, tokenizer, test_size=args.test_size, batch_size=args.batch_size
)
num_senses = len(sense_to_id)
model = WordSenseModel(args.model_name, num_senses).to(device)
optimizer = AdamW(model.parameters(), lr=args.learning_rate)
scheduler = CosineAnnealingLR(optimizer, T_max=args.num_epochs, eta_min=1e-6)
criterion = nn.CrossEntropyLoss()
scaler = GradScaler(enabled=False) # 不使用混合精度,保证兼容性
train_losses = []
val_accuracies = []
best_val_accuracy = 0.0
start_epoch = 0
# EarlyStopping 配置
patience = 5
early_stopping_counter = 0
if args.resume_from_checkpoint:
checkpoint_path = os.path.join(args.output_dir, 'best_model.pt')
if os.path.exists(checkpoint_path):
print(f"恢复训练: 加载 {checkpoint_path}")
checkpoint = torch.load(checkpoint_path, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
best_val_accuracy = checkpoint.get('val_accuracy', 0.0)
start_epoch = checkpoint.get('epoch', 0)
print(f"从第 {start_epoch} 轮继续训练,最佳验证准确率 {best_val_accuracy:.4f}")
print("开始训练...\n")
total_start_time = time.time()
for epoch in range(start_epoch, args.num_epochs):
model.train()
running_loss = 0.0
pbar = tqdm(train_dataloader, desc=f"Epoch {epoch+1}/{args.num_epochs}", unit="batch")
for batch in pbar:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch['token_type_ids'].to(device)
word_mask = batch['word_mask'].to(device)
sense_ids = batch['sense_id'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask, token_type_ids, word_mask)
loss = criterion(outputs, sense_ids)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scaler.update()
scheduler.step()
running_loss += loss.item()
pbar.set_postfix(loss=loss.item())
avg_loss = running_loss / len(train_dataloader)
train_losses.append(avg_loss)
# 验证
model.eval()
val_preds = []
val_true = []
with torch.no_grad():
for batch in val_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
token_type_ids = batch['token_type_ids'].to(device)
word_mask = batch['word_mask'].to(device)
sense_ids = batch['sense_id'].to(device)
outputs = model(input_ids, attention_mask, token_type_ids, word_mask)
_, preds = torch.max(outputs, dim=1)
val_preds.extend(preds.cpu().tolist())
val_true.extend(sense_ids.cpu().tolist())
val_accuracy = accuracy_score(val_true, val_preds)
val_accuracies.append(val_accuracy)
print(f"\n[第 {epoch+1}/{args.num_epochs} 轮] Loss: {avg_loss:.4f} | Val Acc: {val_accuracy:.4f}")
# 保存最佳模型
if val_accuracy > best_val_accuracy:
best_val_accuracy = val_accuracy
early_stopping_counter = 0 # 重置
best_model_path = os.path.join(args.output_dir, 'best_model.pt')
torch.save({
'model_state_dict': model.state_dict(),
'sense_to_id': sense_to_id,
'id_to_sense': id_to_sense,
'val_accuracy': val_accuracy,
'epoch': epoch+1,
'model_name': args.model_name
}, best_model_path)
print(f"✅ 保存新的最佳模型: {best_model_path}")
else:
early_stopping_counter += 1
print(f"⚠️ 验证集准确率连续 {early_stopping_counter} 次未提升")
# EarlyStopping
if early_stopping_counter >= patience:
print(f"⛔ EarlyStopping: 连续 {patience} 次验证集准确率未提升,提前停止训练")
break
print("-" * 50)
# 保存最终模型
final_model_path = os.path.join(args.output_dir, 'final_model.pt')
torch.save(model.state_dict(), final_model_path)
print(f"✅ 保存最终模型到: {final_model_path}")
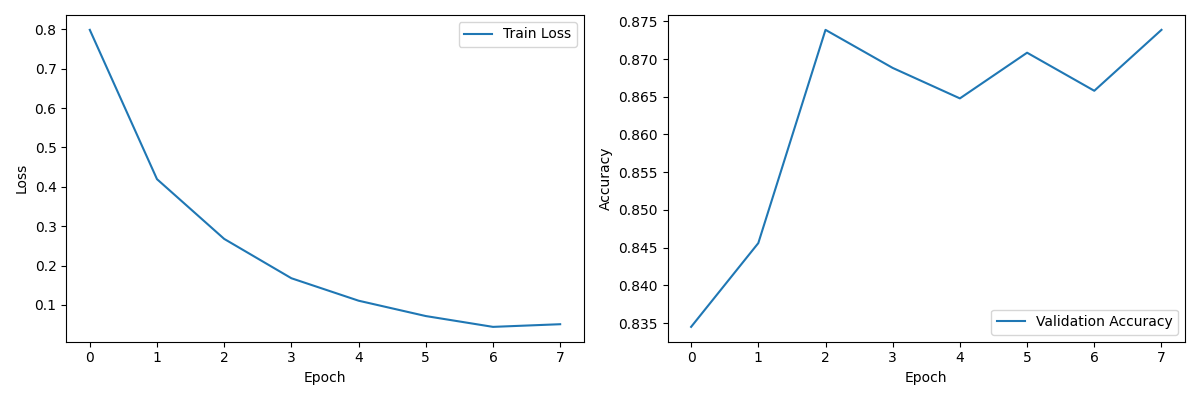
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label="Train Loss")
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(val_accuracies, label="Validation Accuracy")
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
final_plot_path = os.path.join(args.output_dir, 'training_plot.png')
plt.savefig(final_plot_path)
plt.close()
print(f"📈 保存训练曲线到: {final_plot_path}")
total_time = time.time() - total_start_time
print(f"\n训练完成!总耗时: {total_time/60:.2f} 分钟 | 最佳验证准确率: {best_val_accuracy:.4f}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--data_file", type=str, help="单数据文件路径")
parser.add_argument("--data_files", type=str, help="多数据文件路径(逗号分隔)")
parser.add_argument("--model_name", type=str, default="bert-base-multilingual-cased")
parser.add_argument("--output_dir", type=str, default="./output")
parser.add_argument("--num_epochs", type=int, default=30)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--learning_rate", type=float, default=2e-5)
parser.add_argument("--test_size", type=float, default=0.2)
parser.add_argument("--resume_from_checkpoint", action='store_true')
args = parser.parse_args()
if not args.data_file and not args.data_files:
parser.error("至少需要提供 --data_file 或 --data_files")
train(args)
如果你想更加方便,你可以参考我的,再写一个交互性脚本来管理多个词义消歧模型的训练。
主要功能:
-
训练任务管理:
- 预定义了多个训练任务,包括俄语的"путь"(路)、"дорога"(道路)和中文的"道路"
- 每个任务使用特定的数据文件、输出目录和预训练模型
- 俄语任务使用DeepPavlov/rubert-base-cased模型,中文任务使用bert-base-multilingual-cased
-
交互式菜单:
- 提供清晰的命令行界面,显示所有可用训练选项
- 允许用户选择单个训练任务或执行所有任务
- 包含退出程序选项
-
训练参数配置:
- 统一设置了优化后的训练参数(轮数、批次大小、学习率等)
- 通过命令行调用train.py(即之前的训练脚本)执行实际训练
-
断点续训支持:
- 检查是否存在之前的模型检查点文件
- 允许用户选择是否继续之前的训练进度
-
用户体验优化:
- 提供清晰的训练开始和完成提示
- 显示训练耗时统计
- 支持键盘中断处理
import subprocess
import os
import sys
import time
def clear_screen():
"""清除屏幕"""
os.system('cls' if os.name == 'nt' else 'clear')
# 获取虚拟环境的 Python 解释器
venv_python = os.path.join('venv', 'Scripts', 'python.exe')
# 训练配置
training_jobs = [
{
'data_file': 'путь_data.csv',
'output_dir': 'output_путь',
'description': '训练 путь',
'model_name': 'DeepPavlov/rubert-base-cased'
},
{
'data_file': 'дорога_data.csv',
'output_dir': 'output_дорога',
'description': '训练 дорога',
'model_name': 'DeepPavlov/rubert-base-cased'
},
{
'data_file': '道路_data.csv',
'output_dir': 'output_道路',
'description': '训练 道路',
'model_name': 'bert-base-multilingual-cased'
}
]
# 统一训练参数(已优化)
num_epochs = 12
batch_size = 64
learning_rate = 3e-5
test_size = 0.2
def run_training(job_index):
"""运行指定索引的训练任务"""
job = training_jobs[job_index]
print("\n=====================================")
print(f"开始 {job['description']} 的训练...")
print("=====================================")
# 检查是否存在 best_model.pt 以判断是否续训
resume = False
checkpoint_path = os.path.join(job['output_dir'], 'best_model.pt')
if os.path.exists(checkpoint_path):
choice = input(f"检测到 {checkpoint_path},是否接着上次训练?(Y/n): ").strip().lower()
if choice in ('', 'y', 'yes'):
resume = True
cmd = [
venv_python, 'train.py',
'--data_file', job['data_file'],
'--output_dir', job['output_dir'],
'--num_epochs', str(num_epochs),
'--batch_size', str(batch_size),
'--learning_rate', str(learning_rate),
'--test_size', str(test_size),
'--model_name', job['model_name'],
]
if resume:
cmd.append('--resume_from_checkpoint')
start_time = time.time()
subprocess.run(cmd)
elapsed = time.time() - start_time
print("\n=====================================")
print(f"{job['description']} 训练完成!用时 {elapsed:.2f} 秒")
print("=====================================")
def show_menu():
"""显示交互式菜单"""
clear_screen()
print("\n====== 模型训练选择菜单 ======")
print("请选择要训练的模型:")
for i, job in enumerate(training_jobs):
print(f"{i+1}. {job['description']} (模型: {job['model_name'].split('/')[-1]})")
print("4. 训练所有模型")
print("0. 退出程序")
print("==============================")
while True:
try:
choice = int(input("\n请输入选项 (0-4): "))
if 0 <= choice <= 4:
return choice
else:
print("无效选择,请输入 0-4 之间的数字")
except ValueError:
print("请输入有效的数字")
def main():
while True:
choice = show_menu()
if choice == 0:
print("\n退出程序。再见!")
sys.exit(0)
elif choice == 4:
# 训练全部模型
for i in range(len(training_jobs)):
run_training(i)
input("\n按 Enter 键返回主菜单...")
else:
# 训练选择的特定模型
run_training(choice - 1)
input("\n按 Enter 键返回主菜单...")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\n\n程序被用户中断。退出...")
sys.exit(0)
如果你刚好是Windows用户,只会点鼠标,那么恭喜你,我还有一个锦囊。
双击bat脚本
@echo off
chcp 65001
echo ======================================
echo 词义消歧模型批量训练脚本
echo ======================================
call venv\Scripts\activate.bat
python "train_all.py"
echo ======================================
echo 全部训练完成!
echo ======================================
pause
第四部分 使用模型来预测句子
训练完了之后,你可能会看见这样的字眼。准确率0.41
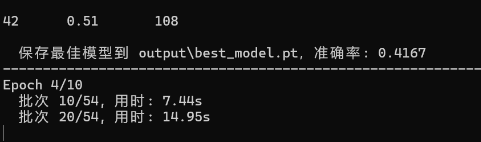
但是如果你像我刚刚第二部分那样,精心准备了训练集的话,大概会看见这样的字眼:

预测脚本,使用该脚本可以使用模型来输入例句来预测。
import torch
import argparse
from transformers import AutoTokenizer
from model import WordSenseModel
# 1. 加载模型
def load_model(model_path, device):
checkpoint = torch.load(model_path, map_location=device)
sense_to_id = checkpoint['sense_to_id']
id_to_sense = checkpoint['id_to_sense']
# 手动创建一些常见的目标词
target_words = ['путь', 'дорога', '道路',]
# 为每个词义手动分配一个目标词
sense_to_word = {}
for _, sense in id_to_sense.items():
# 这里我们需要根据释义内容来判断它对应的目标词
# 由于我们不知道具体的映射关系,这里使用一种简单的方法:让用户选择
sense_to_word[sense] = sense
model_name = checkpoint.get('model_name', 'bert-base-multilingual-cased')
model = WordSenseModel(model_name, len(sense_to_id))
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
model.eval()
print(f"模型已加载,验证准确率: {checkpoint.get('val_accuracy', 'N/A'):.4f}")
return model, sense_to_id, id_to_sense, sense_to_word, model_name, target_words
# 2. 预测词义
def predict_word_sense(sentence, target_word, model, tokenizer, id_to_sense, device):
model.eval()
encoding = tokenizer(
sentence,
add_special_tokens=True,
max_length=128,
return_token_type_ids=True,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt'
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
token_type_ids = encoding['token_type_ids'].to(device)
word_mask = torch.ones(1, 128).to(device) # 简化处理
with torch.no_grad():
outputs = model(input_ids, attention_mask, token_type_ids, word_mask)
probs = torch.nn.functional.softmax(outputs, dim=1)
# 获取所有词义的概率
all_probs = {}
for idx, sense in id_to_sense.items():
all_probs[sense] = probs[0, int(idx)].item()
# 按概率排序
sorted_probs = {k: v for k, v in sorted(all_probs.items(), key=lambda item: item[1], reverse=True)}
# 找出最可能的释义
if sorted_probs:
top_sense = list(sorted_probs.keys())[0]
top_prob = sorted_probs[top_sense]
return top_sense, top_prob, sorted_probs
else:
return None, None, None
# 3. 主程序
def main(args):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
print(f"加载模型 {args.model_path}...")
model, sense_to_id, id_to_sense, sense_to_word, model_name, target_words = load_model(args.model_path, device)
print(f"加载分词器 {model_name}...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 输出支持的目标词
print(f"预先定义的目标词: {', '.join(target_words)}")
# 在首次运行时,让用户选择要使用的目标词
print("\n请选择一个目标词:")
for i, word in enumerate(target_words):
print(f"{i+1}. {word}")
selected_idx = -1
while True:
sentence = input("\n请输入句子 (输入 'exit' 退出): ")
if sentence.lower() == 'exit':
break
if selected_idx < 0:
try:
selected_idx = int(input("请选择目标词编号: ")) - 1
if not (0 <= selected_idx < len(target_words)):
print(f"无效编号,请输入 1-{len(target_words)} 之间的数字")
selected_idx = -1
continue
except ValueError:
print("请输入有效的数字")
continue
target_word = target_words[selected_idx]
print(f"使用目标词: {target_word}")
predicted_sense, confidence, all_probs = predict_word_sense(
sentence, target_word, model, tokenizer, id_to_sense, device
)
if predicted_sense is None:
print("错误:无法预测释义,请检查模型训练!")
continue
print("\n预测结果:")
print(f"句子: {sentence}")
print(f"目标词: {target_word}")
print(f"预测释义: {predicted_sense} (置信度: {confidence:.4f})")
print("\n所有释义及概率:")
count = 0
for sense, prob in all_probs.items():
print(f" {prob:.4f} - {sense}")
count += 1
if count >= 5: # 只显示前5个结果
print(" ...")
break
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="使用词义消歧模型进行预测")
parser.add_argument("--model_path", type=str, required=True, help="模型文件路径")
args = parser.parse_args()
main(args)
第五部分 讲故事环节
你可以使用这个脚本来画饼图或者条形图,来放进你的论文里。
import pandas as pd
import os
import matplotlib.pyplot as plt
import matplotlib
# 设置字体,防止中文或俄文乱码
matplotlib.rcParams['font.family'] = 'SimHei' # 黑体(适合Windows)
# matplotlib.rcParams['font.family'] = 'Microsoft YaHei' # 微软雅黑(也是可以的)
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 列出当前目录下所有CSV文件
csv_files = [f for f in os.listdir('.') if f.endswith('.csv')]
# 如果没有找到CSV文件
if not csv_files:
print("⚠️ 当前目录下没有找到任何CSV文件!")
exit()
print("请从以下CSV文件中选择一个进行统计:")
for idx, filename in enumerate(csv_files):
print(f"{idx + 1}. {filename}")
while True:
try:
choice = int(input("请输入文件编号(例如 1):"))
if 1 <= choice <= len(csv_files):
selected_file = csv_files[choice - 1]
break
else:
print("❌ 输入的编号无效,请重新输入。")
except ValueError:
print("❌ 请输入数字编号。")
print(f"✅ 你选择的文件是:{selected_file}")
df = pd.read_csv(selected_file, encoding="utf-8")
sense_counts = df['sense_id'].value_counts()
print("\n每个 sense_id 出现的次数:")
print(sense_counts)
output_path = f"sense_id_statistics_from_{selected_file}"
sense_counts.to_csv(output_path, encoding="utf-8")
print(f"\n✅ 统计结果已保存到:{output_path}")
# 计算总样本数
total_examples = len(df)
# --- 绘制条形图 ---
plt.figure(figsize=(10, 6))
sense_counts.plot(kind='bar')
plt.title(f'Sense ID 统计 - 条形图 (总样本数: {total_examples})')
plt.xlabel('Sense ID')
plt.ylabel('数量')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
# 在左下角添加每个sense_id的数量信息
text_content = "每个意思的句子数:\n"
for sense_id, count in sense_counts.items():
text_content += f"{sense_id}: {count}句\n"
plt.figtext(0.01, 0.01, text_content, fontsize=8, va='bottom')
plt.savefig(f"bar_chart_{selected_file}.png")
plt.show()
print(f"✅ 条形图已保存到 bar_chart_{selected_file}.png")
# --- 绘制饼图 ---
plt.figure(figsize=(8, 8))
sense_counts.plot(kind='pie', autopct='%1.1f%%')
plt.title(f'Sense ID 统计 - 饼图 (总样本数: {total_examples})')
plt.ylabel('')
plt.tight_layout()
# 在饼图左下角添加每个sense_id的数量信息
text_content = "每个意思的句子数:\n"
for sense_id, count in sense_counts.items():
text_content += f"{sense_id}: {count}句\n"
plt.figtext(0.01, 0.01, text_content, fontsize=8, va='bottom')
plt.savefig(f"pie_chart_{selected_file}.png")
plt.show()
print(f"✅ 饼图已保存到 pie_chart_{selected_file}.png")
不出意外,图是这样的:
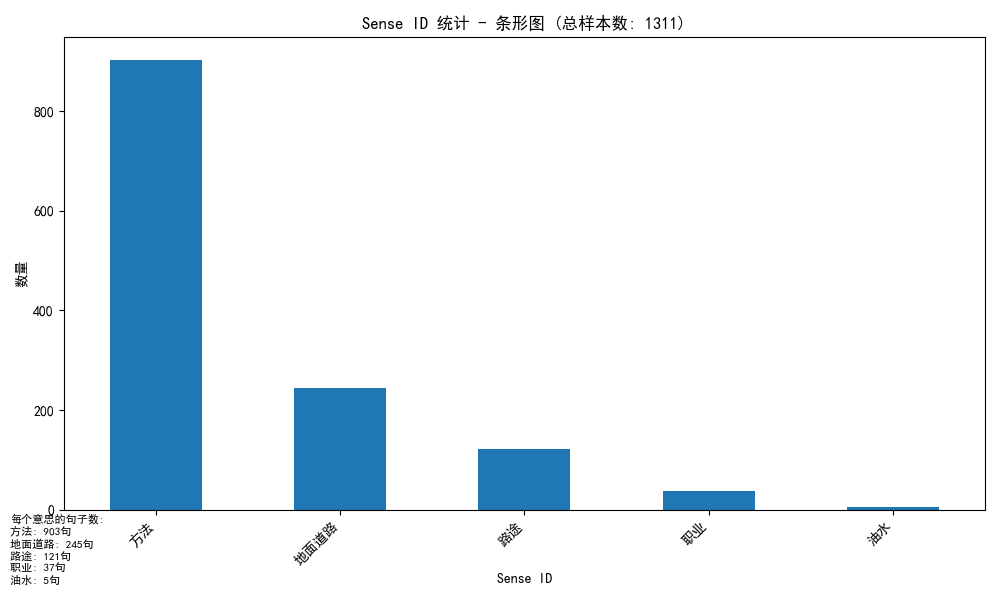
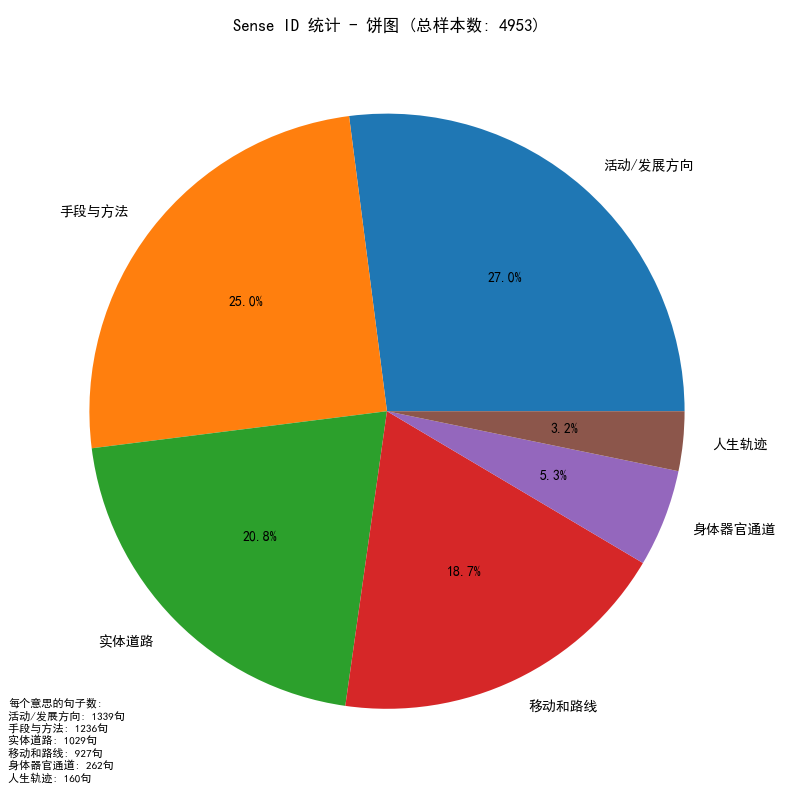
除此之外,你的文件夹目录里的output_词汇文件夹里还有这样子的图,来展示训练时候的数据,会很有说服力:
总结
本人会一点计算机。